Using the Kani Rust Verifier on Tokio Bytes
In this post we’ll apply the Kani Rust Verifier (or Kani for short), our open-source formal verification tool that can prove properties about Rust code, to an example from Tokio.
Tokio is an asynchronous runtime for Rust programs, meaning that it abstracts the low-level async capabilities of the language into useful building blocks (such as providing an executor for the scheduling and execution of async tasks). The aim of Tokio is to provide the “building blocks needed for writing network applications [with] the flexibility to target a wide range of systems, from large servers with dozens of cores to small embedded devices”. In this post we will focus on a low-level component of the Tokio stack and proving properties about a core data structure.
Diving into Bytes::BytesMut
At the bottom of the Tokio stack is the Bytes library, a “rich set of utilities for manipulating byte arrays”, which reflects the fact that networking applications, at their core, have to manipulate byte streams. Inside the library are two container types:
Bytes: a cheaply cloneable and sliceable chunk of contiguous memoryBytesMut: a unique reference to a (potentially shared) contiguous slice of memory
As the names suggest, the bytes pointed to by a Bytes instance are immutable whereas they are mutable through a BytesMut instance.
In this post we’ll focus on BytesMut.
Let’s start with its definition:
pub struct BytesMut {
ptr: NonNull<u8>,
len: usize,
cap: usize,
data: *mut Shared,
}
struct Shared {
vec: Vec<u8>,
original_capacity_repr: usize,
ref_count: AtomicUsize,
}
The straightforward part is the first three fields.
Similar to a Vec<u8>, we have a pointer ptr to the backing buffer of size cap bytes with len bytes currently in use.
The field data is a bit trickier because it handles sharing of the backing buffer.
In particular, data is used to distinguish between two representation modes: KIND_VEC and KIND_ARC.
- A
KIND_VECis used when the backing buffer is only pointed to byptr. In this case,datais not used as a pointer but instead contains a sentinel value (the bottom bit is set to'0b1) to mark that we’re using this representation. - A
KIND_ARCis used when the backing buffer is shared by multipleBytesMutinstances. In this case, each instance’sdatafield points to a singleSharedobject whoseref_countkeeps track of the number of aliases. In order for this aliasing to be safe, the implementation must ensure that each instanceptrfield points to a disjoint part of the slice. [Additionally, the rules for pointer alignment, and the fact thatSharedhasalign > 1, ensure that we will never mix up representations.]
As a user of BytesMut you don’t need to worry about this distinction.
Under the hood, the implementation will switch representations as required [and, within the library implementation, we can use the private method kind() to query the representation of a given instance].
A simplified state machine of when the representation changes is as follows:
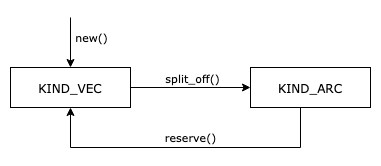
Constructors such as new() (and others like with_capacity() and zeroed()) create fresh instances of BytesMut.
By construction, these are KIND_VEC since there is exactly one instance that points to the backing buffer: the one we are creating.
Operations like split_off(&mut self, at: usize) -> BytesMut (and others like split() and split_to()) allow us to split the bytes into two segments.
In the case of split_off, we split at the index at so that afterwards self contains elements [0, at) and the returned BytesMut contains elements [at, cap).
Internally this means that, after the call, both self and the returned BytesMut must be KIND_ARC.
For example:
let mut a = BytesMut::from(&b"helloworld"[..]);
// After the constructor, memory looks like:
//
// 0 1 2 3 4 5 6 7 8 9
// a.ptr o──────────► [ h e l l o w o r l d ]
// a.len = 10
// a.cap = 10
// a.data = 0x1 (KIND_VEC)
let mut b = a.split_off(5);
// After splitting, memory looks like:
//
// 0 1 2 3 4 5 6 7 8 9
// a.ptr o──────────► [ h e l l o w o r l d ]
// a.len = 5 ▲
// a.cap = 5 │
// a.data = &shared (KIND_ARC) │
// │
// b.ptr o────────────────────────┘
// b.len = 5
// b.cap = 5
// b.data = &shared (KIND_ARC)
//
// shared.ref_count = 2
assert_eq!(&a[..], b"hello");
assert_eq!(&b[..], b"world");
Notice that after the split_off operation, both a and b share the same backing buffer (ref_count is 2) but point to disjoint slices.
Finally, it is possible for the representation to return from KIND_ARC back to KIND_VEC using reserve(&mut self, additional:usize), which ensures that there is capacity for at least additional more bytes to be inserted.
If self does not have sufficient space, then a fresh backing buffer is allocated and the contents of the original are copied over.
Continuing from our example above:
b.reserve(3);
// Now memory looks like:
// 0 1 2 3 4 5 6 7 8 9
// a.ptr o──────────► [ h e l l o w o r l d ]
// a.len = 5
// a.cap = 5
// a.data = &shared (KIND_ARC)
// 0 1 2 3 4 5 6 7
// b.ptr o──────────► [ w o r l d . . .] (fresh buffer)
// b.len = 5
// b.cap = 8
// b.data = 0x1 (KIND_VEC)
//
// shared.ref_count = 1
After the reserve operation, the ref_count is 1 since only a has elements in the original backing buffer and a fresh buffer has been allocated for b with sufficient space for 3 additional bytes.1
Using Kani
To show how Tokio developers could integrate Kani proofs, we will add our examples to (a fork of) the BytesMut implementation.
This has the advantage that the implementation details will be visible to our proofs.
Like previous posts, all the code and instructions for reproducing the results of this post yourself are available (see Further Reading).
A simple example
Let’s begin with a straightforward test that could equally well be a unit test: the code we used above.
#[cfg(kani)]
mod verification {
#[kani::proof]
fn test_kind_representation_change() {
let mut a = BytesMut::from(&b"helloworld"[..]);
assert!(a.kind() == KIND_VEC);
let mut b = a.split_off(5);
assert!(a.kind() == KIND_ARC);
assert!(b.kind() == KIND_ARC);
assert!(&a[..] == b"hello");
assert!(&b[..] == b"world");
b.reserve(3);
assert!(b.kind() == KIND_VEC);
}
}
As you’d expect, this has no problems and confirms the behavior explained above. In this particular case, there is no advantage to using Kani rather than running the test, but it is nice to show Kani handling code that internally uses unsafe Rust.
$ cargo kani --harness test_kind_representation_change
# --snip--
VERIFICATION:- SUCCESSFUL
Representation invariants and ghost state
In our earlier post on using Kani with the Rust Standard Library, we introduced representation invariants: properties that should always hold for any instance of a data type.
If an instance of a data type satisfies its representation invariant we say the instance is well-formed.
Since BytesMut has two different representations we need to think about what properties each of them need.
Let’s begin with a property that should hold regardless of the representation: the instance’s length must be within bounds of its capacity.
We will also add calls to appropriate methods, to be defined, for each representation kind.
In Kani, we can write a method is_valid to express when a type T is well-formed:
impl BytesMut {
fn is_valid(&self) -> bool {
self.len <= self.cap
&& match self.kind() {
KIND_VEC => self.is_valid_kind_vec(),
KIND_ARC => self.is_valid_kind_arc(),
_ => false,
}
}
}
For KIND_VEC we need to know a bit more about how a BytesMut is constructed.
The implementation, which we’ve slightly simplified (just in this post), is as follows.
Internally the constructor allocates the backing buffer inside a Vec<u8> with sufficient capacity.
The BytesMut instance is then built out of the fields of the vector.
impl BytesMut {
pub fn with_capacity(capacity: usize) -> BytesMut {
BytesMut::from_vec(Vec::with_capacity(capacity)) //< (1)
}
pub(crate) fn from_vec(mut vec: Vec<u8>) -> BytesMut {
let ptr = vptr(vec.as_mut_ptr()); //< (2)
let len = vec.len(); //<
let cap = vec.capacity(); //<
mem::forget(vec); //< (3)
let data = KIND_VEC; //< (4)
BytesMut {
ptr,
len,
cap,
data: data as *mut _,
}
}
}
In the above, we’ve annotated the steps:
- A
Vec<u8>is used to allocate a buffer of the requested capacity - Set
ptrto point to thevec’s buffer (as_mut_ptr()returns the raw pointer (*mut u8) andvptr(), an internal function, turns this into aNonNull<u8>) - Use
mem::forgetto ensure thatvec’s destructor will not run whenfrom_vecreturns (notice thatvecis moved intofrom_vec). This is essential to ensure that the buffer pointed to byptrremains valid. - Set
datatoKIND_VEC(=0b1), which is subsequently cast to a raw pointer*mut Shared
This is interesting, but unfortunately there is not a great deal more we can say for is_valid_kind_vec().
If we have an instance using KIND_VEC then we know that the ptr and cap must be related to the “original vector”.
For example, immediately after construction, we know ptr must be exactly vec’s buffer and similarly for cap.
However, we no longer have access to this vec, so for now we will make our well-formedness check a no-op.
[Don’t worry, we will return to this later!]
fn is_valid_kind_vec(&self) -> bool {
assert!(self.kind() == KIND_VEC);
true
}
Let’s now turn to the KIND_ARC case.
Here we are more fortunate because we have the Shared object pointed to by the data field of the BytesMut instance.
As a reminder, here’s what the Shared struct looks like:
struct Shared {
vec: Vec<u8>,
original_capacity_repr: usize,
ref_count: AtomicUsize,
}
The ref_count is the number of references (including the instance, itself) to the backing buffer.
For this reason, we know that ref_count must be at least 1.
Secondly, vec is the “original vector” that we have derived our instance’s slice from.
[We will ignore original_capacity_repr which is used to ensure that reserve always allocates sufficient bytes.]
Having this “in our hands” is useful because it must be the case that the ptr is within vec’s buffer, and similarly for capacity.
Putting this together:
fn is_valid_kind_arc(&self) -> bool {
assert!(self.kind() == KIND_ARC);
let shared: *mut Shared = self.data as _;
unsafe {
let ref_count = (*shared).ref_count.load(Ordering::Relaxed);
let valid_ref_count = 1 <= ref_count;
let vec_ptr = (*shared).vec.as_mut_ptr();
let vec_cap = (*shared).vec.capacity();
let vec_end_ptr = vec_ptr.offset(vec_cap as isize);
let ptr = self.ptr.as_ptr();
let ptr_in_bounds = vec_ptr <= ptr && ptr <= vec_end_ptr;
let cap_in_bounds = self.cap <= vec_cap;
valid_ref_count && ptr_in_bounds && cap_in_bounds
}
}
This gives us an idea!
What if we could keep track of the original vector for KIND_VEC too?
The use of program state that is just for verification is known as ghost state, originally called auxiliary variables.
You can think of it as metadata only for the purposes of Kani, that can be ignored by compilation (and hence has no runtime cost2).
Here’s what we need:
pub struct BytesMut {
//--snip-- (all the original fields)
#[cfg(kani)]
ghost: Ghost,
}
// State used by verification
#[cfg(kani)]
struct Ghost {
original_vec_ptr: NonNull<u8>,
original_len: usize,
original_cap: usize,
}
impl BytesMut {
pub(crate) fn from_vec(mut vec: Vec<u8>) -> BytesMut {
//--snip-- (the constructor as before)
BytesMut {
ptr,
len,
cap,
data: data as *mut _,
#[cfg(kani)]
ghost: Ghost {
original_vec_ptr: ptr,
original_len: len,
original_cap: cap,
},
}
}
}
The idea is that when we construct a BytesMut we’ll “save” information about the original vec so that we can use it later.
Here we are fortunate that BytesMut only has one “root constructor” so we only have to make a single change.
With this in hand, we can re-write our well-formedness check for KIND_VEC.
Notice that we allow ptr and cap so long as they are in bounds (rather than being an exact match).
This is because there are BytesMut operations, such as advance, that modify these fields.
fn is_valid_kind_vec(&self) -> bool {
assert!(self.kind() == KIND_VEC);
let vec_ptr = self.ghost.original_vec_ptr.as_ptr();
let vec_cap = self.ghost.original_cap;
let vec_end_ptr = unsafe { vec_ptr.offset(vec_cap as isize) };
let ptr = self.ptr.as_ptr();
let ptr_in_bounds = vec_ptr <= ptr && ptr <= vec_end_ptr;
let cap_in_bounds = self.cap <= vec_cap;
ptr_in_bounds && cap_in_bounds
}
Phew, that was a bit of work!
But now we have a property (a representation invariant) that should always hold for any instance of BytesMut.
A proof about with_capacity()
Let’s try and use our representation invariant.
How about proving that the BytesMut constructor with_capacity() always returns a well-formed instance?
In earlier posts we introduced Kani any<T>().
This is a feature that informally generates “any T value”.
This is not the same as a randomly chosen concrete value (as in fuzzing) but rather a symbolic value that represents any possible value of the appropriate type.
The key idea is that we can use any in a Kani harness to verify the behavior of our code with respect to all possible values of an input (rather than having to exhaustively enumerate them).
For example, we can write a harness that uses any<usize>() to call with_capacity and subsequently assert that the returned BytesMut instance is well-formed.
#[cfg(kani)]
mod verification {
use super::*;
#[kani::proof]
fn with_capacity_returns_well_formed_bytes_mut() {
let cap = kani::any();
kani::assume(0 < cap); //< (1)
kani::assume(cap < MAX_KANI_ALLOCATION); //< (2)
let a = BytesMut::with_capacity(cap);
assert!(a.kind() == KIND_VEC);
assert!(a.is_valid());
}
}
There are two assumptions that we will return to shortly, but first we note Kani has no problem proving this harness:
$ cargo kani --harness with_capacity_returns_well_formed_bytes_mut --output-format terse
#--snip--
VERIFICATION RESULT:
** 0 of 410 failed
VERIFICATION:- SUCCESSFUL
The two assumptions are needed for different reasons.
The first assumption (1) avoids constructing a vector with capacity 0.
This doesn’t sound tricky except that the Vec implementation uses a dangling pointer to represent vectors with capacity 0.
And we have an open question with the unsafe-wg about what operations are legal on such a dangling pointer.
For now, using this assumption avoids this case.
The second assumption(2) is necessary because Kani’s abstract machine uses a fixed (but parameterizable) number of bits in a pointer for its analysis (to track allocated objects).
By default, Kani’s maximum allocation is 2^47 bytes (whereas the documentation for vec states a maximum allocation of isize::MAX == 2^63 - 1 bytes).
Currently Kani does not error if an allocation exceeds this bound so this assumption avoids this case.
With these two assumptions, Kani verifies the proof harness effectively checks all invocations of with_capacity() with cap ranging from [1..2^47).
A proof about split_off
Next let’s turn our attention to the split_off method.
We would like to show that the method maintains our representation invariant: for any well-formed self: BytesMut instance (i.e., that satisfies is_valid()) calling split_off leaves self well-formed and returns a new well-formed instance.
Here’s a proof harness where we add an assumption at (1) to handle the fact that the docs state that split_off panics if at > capacity.
#[cfg(kani)]
mod verification {
#[kani::proof]
fn split_off_maintains_well_formed() {
let mut a = kani::any();
let at = kani::any();
kani::assume(at <= a.capacity()); //< (1)
let b = a.split_off(at);
assert!(a.is_valid());
assert!(b.is_valid());
}
}
We need one more ingredient to make this work.
Unlike uses of kani::any() in past blog posts, we need kani::any() to return a symbolic heap-allocated object for a (i.e., the backing buffer pointed to by buf).
In this case, Kani provides the Arbitrary trait.
This requires us to implement any to construct a symbolic well-formed instance.
In effect, we need to write a “verification-friendly” constructor that uses symbolic values (e.g., for the size of the backing buffer) to call other methods (e.g., with_capacity()) to ensure proper heap-allocation.
#[cfg(kani)]
impl kani::Arbitrary for BytesMut {
fn any() -> Self {
let cap = kani::any();
kani::assume(0 < cap);
kani::assume(cap < MAX_KANI_ALLOCATION);
let b = BytesMut::with_capacity(cap); //< (1)
let make_kind_arc = kani::any(); //< (2)
if make_kind_arc {
// --snip-- (elided)
} else {
// len set within buffer cap
let len = kani::any();
kani::assume(len <= cap);
b.len = len; //< (3)
}
assert!(b.is_valid());
b
}
}
At (1) we create a new BytesMut instance using a symbolic capacity cap.
Thanks to our previous proof harness with_capacity_returns_well_formed_bytes_mut we know this returns a well-formed instance using KIND_VEC.
At (2) we use kani::any() to pick a symbolic Boolean value, which we use to decide whether to turn the instance into a KIND_ARC or to remain as a KIND_VEC.
By making make_kind_arc symbolic we enable Kani to explore both possibilities (i.e., produce both well-formed KIND_ARC and KIND_VEC instances).
For brevity, we’ll focus on the case where we remain as a KIND_VEC.
After (1) we have an empty (len == 0) instance using KIND_VEC.
To make a less constrained instance at (3) we update len to index anywhere between [0, cap].3
The KIND_ARC case is similar, except we deal with b.data too (e.g., setting ref_count to a symbolic value where 1 <= ref_count).
Suitably equiped with this symbolic constructor, Kani takes about a minute to analyze our harness successfully.
$ cargo kani --harness split_off_maintains_well_formed --output-format terse
#--snip--
VERIFICATION RESULT:
** 0 of 410 failed
VERIFICATION:- SUCCESSFUL
This result proves a specification for split_off:
- Assuming that the instance is well-formed and the requested index
atis within bounds (the precondition) - Then calling
split_offwill not panic and the updated instance and its return value are both well-formed (the postcondition).
Why does this matter?
This result gives us assurance that this is true for any well-formed BytesMut (using either representation).
A way to approximate the power of this approach is to think about the number of test cases we would need to write to get the same level of assurance.
Just taking the case of a KIND_VEC, we consider any sized backing buffer size up to MAX_KANI_ALLOCATION (= 2^47) bytes and allow len to take any index within this range.
This is on the order of 2^47 * 2^47 = 2^94 different test cases (a large number!).
About specifications
Like all results from automated reasoning tools, the result we have for split_off hinges on assumptions that must be reviewed to ensure they are reasonable.
The most important consideration is the specification itself, which you can think of as being a “contract” that tells you if the client or user of BytesMut adheres to the specification’s requirements (i.e., the precondition) then the proof result guarantees certain properties (i.e., the postcondition).
For example, if a client performed unsafe operations to make a BytesMut instance not well-formed (such as setting ptr to point outside of the backing buffer) then the proof result no longer applies (because the precondition is not satisfied).
In this sense, it’s important to ensure that the precondition accurately reflects how the method will be used.
Similar considerations apply to the postcondition.
Notice that the proof harness does not check that split_off performs a split at the index at.
Since we only check for well-formedness, an implementation of split_off that always split at index 0 would satisfy our specification even though it wouldn’t be accurately reflecting our expectations.
A good exercise would be to add appropriate assertions to the proof harness to give us this property too.4
Summary
In this post, we worked with Tokio bytes and focused on its BytesMut implementation.
We encoded a representation invariant using ghost state (program state just for the purpose of verification).
Using Kani we proved that the constructor with_capacity() always returns a well-formed instance and that split_off maintains this invariant and discussed what this specification means.
As future work, we could apply Kani to ensure that all API functions of BytesMut maintain this invariant, which would show that any instance is well-formed.
[In fact, if you look at our code you can see that we implemented proof harnesses for 6 further API functions.]
To test drive Kani yourself, check out our “getting started” guide. We have a one-step install process and examples, including all the code in this post with instructions on reproducing the results yourself, so you can try proving your code today.
Further Reading
- Tokio project
- Tokio bytes
- More on auxiliary variables
- More on representation invariants (lecture 8)
- Code and instructions for reproducing the results in this post
Footnotes
-
You may wonder why the type of
ref_countisAtomicUsizeand not justusize. The reason is thatBytesMutisSendandSync(i.e., safe to send to another thread and safe to share between threads). Consequently, the same backing buffer may be shared byBytesMutinstances owned by different threads.Consider two threads that call
spliton theirBytesMutinstance at the same time. In this case there is a potential race for each thread to incrementshared.ref_count. Imagine ifref_countwas justusizeand each thread effectively triedref_count += 1. The problem is that this involves both a read (to get the current value) and a write (to set the incremented value). This means it is possible to lose an update:Thread 1 || Thread 2 reads ref_count as 2 || || reads ref_count as 2 || compute 2 + 1 || writes ref_count to 3 compute 2 + 1 || writes ref_count to 3 ||This is a bad outcome because it’s now possible for the backing buffer to be dropped (when
ref_countis decremented to0) whilst aBytesMutinstance still points to it (a potential use-after-free error).By using
atomic operationswe are guaranteed that we will never lose an update. So it’s essential that the type ofref_countisAtomicUSize. [In fact, a strict reading of Rust’s atomic memory model, which specifies the behavior of concurrent shared memory programs, is that aref_countimplementation using non-atomics is undefined since it involves a non-atomic data race.] ↩ -
Note that this will change the layout in Kani. ↩
-
You may wonder whether this update to
lenis safe. The valid elements of aBytesMutinstance are between[ptr..ptr+len)so settinglento an arbitrary position (withincap) allows potentially uninitialized memory to be read, which is undefined behavior.Kani’s allocator gives symbolic (but initialized) values for freshly allocated objects. [This is analogous to a custom allocator that always returns initialized (e.g., zeroed) memory.] Under this (more restricted) allocation scheme the update to
lenin our implementation ofany()is safe. In order for Kani to detect this kind of undefined behavior in the future, we will need to add a way to track uninitialized memory. ↩ -
Here’s one possibility:
#[kani::proof] fn split_off_maintains_well_formed() { let mut a: BytesMut = kani::any(); let at = kani::any(); kani::assume(at <= a.capacity()); let b = a.split_off(at); assert!(a.is_valid()); assert!(b.is_valid()); // Additional checks that the operation does what we expect assert!(a.cap == at); unsafe { assert!(b.ptr.as_ptr() == a.ptr.as_ptr().offset(at as isize)); } }